url: https://www.youtube.com/watch?v=mgXSevZmjPc
title: The Fourier Series and Fourier Transform Demystified
channel: Up and Atom
duration: 14m 47s
visited: 2023-06-27The Fourier Series, and the Fourier Transform, can be found almost everywhere. The concept is that we can kind of write almost any function in terms of sine and cosine. But how so? They have a very smooth shape, but things like a square-wave or saw tooth wave have jagged edges.
We need to start at the beginning.
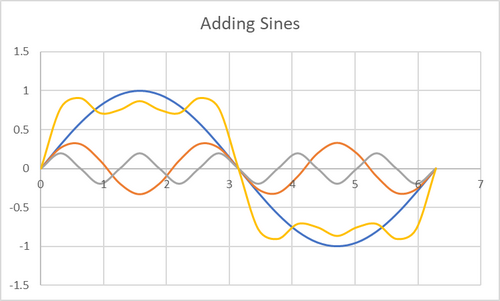
Markdown makes photos challenging… but imagine a regular sine wave, on the interval . Now, imagine on that same interval. It has a smaller frequency. If you add them together, you may see how we begin to approach a new graph. That is, over the same interval, we add together the values of the function.
In that example, you’ll also notice that when the results in the original functions are both the same, the sum gets larger (either positive or negative). And when the signs are opposite, they cancel each other out.
Since our example above has moments that cancel each other out, we want to give our a smaller amplitude, to hinder the effect it has. If we continue to add similar terms, smaller amplitude and frequencies, you’ll see it approaches the square wave.
Above is a small graph made in Excel. The sine waves are different frequency and amplitudes of the sine function and the Yellow is the addition of them. As we continue to add more waves, we’ll get closer to the square wave.
The Fourier Series is an infinite sum, meaning you’ll add infinite waves. Therefore, you’ll eventually reach your exact solution.
Another example is the saw tooth wave. You can start with the following:
What is the point, especially when it involves an infinite sum? In practice, we don’t need to evaluate an infinite sum, but just enough terms to be good enough for the application. The instructor suggests a program to determine the difference between our two functions, the square and sawtooth waves.
Just by knowing the amplitude (coefficient) of the second term, the program could tell the difference.
Finding the Fourier series for a trivial example like this might be more work than it’s worth. However, extending this to different and more general objects helps a computer learn pattern and shape recognition. The difficult part, when comparing objects, is finding the Fourier Series to analyse. That is, what waves make up the shape we are looking at.
The Fourier Transform help determine which waves make up the Fourier Series. It can also pick and remove waves without having to find the Fourier series as well. This help when removing noises in recordings.
The idea is that you give it amplitude vs time function, and you get an amplitude vs frequency function. This happens because the transform decomposes the function into sine and cosine waves. The graph of AvF looks like a bar chart. It is a “frequency domain view of a time domain function.”
Mathematical equation for Fourier transform is
The is the time function we are calculating the Fourier Series for. The exponential term comes from Eulers Formula…
Basically, you can write the exponential in terms of sine and cosine waves. Also, that is for an imaginary component. It handles the general case where there may be different phases required to make up the function.
For the square wave, it ends up looking like . We multiple values from the sine wave and our function to get some results, either positive or negative. When the results are positive, it tells us the results are more correlated. And when the waves are anti-correlated, we will get a negative value. And when there is no correlations, we get 0. In this, the terminology for correlation more or less means the difference between actual and expected, more like a variance, but not.
The integral is a continuous version of the sum. We are summing all of the correlations to determine if the wave is important to the series. If the term is important, its sum will be greater than 0. If the sum is negative, it’s not useless, but just subtracted instead of added because it implies anti-correlation.
For the square wave, the integral of our , and after normalization, we find the sum to be . This means that one-third of the amplitude is used to make the square wave! really cool.
The square wave is only made up of odd sine curves. That is because, there’s one extra ‘hump’ in each odd term to make the resulting summation not 0. Similar reason why the cosine value isn’t seen in this series either.
The Fourier Transform does this process for any frequency, telling us which frequencies go into any function. You can think of it as “Changing the basis of the function in an infinite dimensional space.” What does this mean? We can change the basis of function space, like how we change the basis of a vector space, which is change coordinates to describe the same vector. So, we went from amplitude vs infinite time positions, to amplitude vs infinite frequency values. This is only possible because our sine and cosine waves make up an orthogonal basis. Or, they can be combine to make any function in function space.
The catch is that you need some kind of mathematical description of the input function. This is where algorithms come into play. Plug in for Curiosity Stream. Additional plugin for Nebula.TV.
title: Applied Fourier Analysis
subtitle: From Signal Processing to Medical Imaging
author: Tim Olson
publisher: Springer Science+Business Media, LLC
year: 2017
doi: https://doi.org/10.1007/978-1-4939-7393-4_1Fourier Analysis is at the center of many modern sciences, from Physics and engineering, to population dynamics in biology. Many of the important phenomena in our world are related to periodic phenomena. Understanding frequency based functions, sines and cosines, are eigenfunctions, or “building blocks of the universe.”
Fourier Series involves representing a continuous function on a finite interval with an infinite series, which is similar to the Taylor series.
The Discrete Fourier Transform (DFT) is focused on a function on a finite set of points, referred to as . Being discrete, it’s commonly implemented in technology.
The Continuous Fourier Transform (CFT) extends the Fourier Series to deepen our understanding of connections between physical reality and digital representations.
Quick look at a basic Fourier Series. On an interval we can represent a series expansion:
where…
Ok, so that is a discrete summation of the integration of trigonometric functions on our interval for each value of . We have only just begun the most basic form of Fourier Analysis, which is to separate a function into the various frequencies which represent it.
Interesting to note that the cosine terms are even, and the sine terms are odd. We have decomposed our function into even and odd parts, in addition to individual frequencies. This will be invaluable later.
One limitation of the Fourier Series can be seen in the formulas. You must calculate the integrals, a time consuming and difficult practice. Another limitation is that a Fourier Series is only valid on a finite interval.
The Discrete Fourier Transform (DFT) addresses the problem of calculating an infinite number of integrals by creating a simple matrix that can be on basic finite signals.
Suppose you have a function on an interval, and you need to represent with samples at discrete time points , where . We will let this be a vector:
formula 1.1
The DFT samples cosine and sine terms. The vector representing would be , where of course . Both will go through a complete cycle on the interval of .
We use the sine and cosine vectors to construct the Fourier Matrix , where represents the number of points in our sampled function. We can write the vector as a multiple of these cosine and sine vectors:
equation 1.2
We let represent the coefficients of our sampled sines and cosines. Note, you can easily find if needed. Advantages:
We must address several issues / questions to utilise this approach:
We define the the Fourier Transform as:
The final integral is composed of sine and cosine subsets. These discrete subsets, or samples, of the Fourier Transform generate sampling theory, which we will also look at later.
We use the Continuous Fourier Transform to more easily understand some beautiful phenomena. One such being the uncertainty principle.
A primary goal of science is to provide simple explanations of a phenomenon. A lot of physical phenomena can be explained with sines and cosines.
One such example is the begins with an ordinary differential equation:
One way to solve the equation is to guess the solution takes the form of . That easily leads to the derivatives. Then there is some older, weird logic like this:
But since for any , we just factor it out…
The solution then depends on the above equations, a typical polynomial. We have changed a differential equation into a simple polynomial equation. Then, we can solve with the quadratic equation:
quadratic equation
If the discriminant, , then the solutions are both real and the corresponding solutions to the differential equation will exhibit either exponential growth or decay.
For reference, exponential growth is typical of population growth, like bacteria in a petri dish. An exponential decay is common in situations where a signal is being absorbed as it transmits through a medium. I think calculations of half-life exhibit exponential decay.
Prep for the next topic; conjugates are pairs of binomials with identical terms but parting opposite arithmetic operators in the middle. An example being and .
Fourier Analysis is useful for when . The ’s with be conjugate pairs of one another, which can be denoted as .
Also note that . Hence, a complex exponential solution(s):
It is generally assumed that . If the solution would oscillate forever. However, when , the solution to the differential equation decays exponentially to zero.
The frequency is often called the resonant frequency of the system.
We might want to manipulate output or behaviour of a system:
Simple changes to the way things are represented and stored can save vast amounts of storage space. Compression information without losing quality, transmission, and restoration of information is very valuable, especially in communications.
Using Taylor Series expansion of , show that
To do this, you will need this list of Maclaurin series of common functions. Colin Maclaurin, in the mid-18th century, created this list of when is the point where the derivatives are considered.
Let’s write down what we are looking for
Looking at the middle pattern, It’s really interesting that the combination covers all values of .
Additionally, the Riemann Series Theorem, named after 19th-century German mathematician Bernhard Riemann, states that if an infinite series of real numbers is conditionally convergent, that it does not converge absolutely, the terms can be arranged in a permutation so that the new series converges to an arbitrary real number… or diverges. This implies that a series or real numbers is Absolutely Convergent if and only if it is Unconditionally Convergent.
The series are meant to be absolutely convergent, meaning they can be rearranged without affecting the outcome.
And finally:
Either way:
Now, let’s do a little calculus comparison
We know that
Therefore
Now,
Based on the Maclaurin series for cosine and sine, I’m not getting similar results, but didn’t try too hard as I am pressed on time.
Additionally, try to differentiate and . Do they line up better?
Fourier Analysis is an extension of Linear Algebra. It is the study of sines and cosines, and how they interact and behave in a complex setting. Fourier Analysis is a subtopic of Linear Analysis, which is an extension of Linear Algebra, following the same rules, except that we allow an infinite number of variables, or dimensions.
Basic concepts of Linear Analysis are the same as Linear Algebra. Begin with the idea of a vector space, which involves objects and operations.
2 types of objects:
2 types of operations:
We now have the basics in a vector space. Consider that we are , and we have a matrix. According to Linear Algebra, if we have a matrix within a vector space, it holds that
That is, the matrix respects the linear arithmetic of the vector space.
The dot product is used extensively in Linear Algebra, and defined as:
definition of dot-product
It has many implications, one being it defines the notion of distance:
notion of distance
This can be seen as an extension of the Pythagorean theorem. Sum of the squares equals the final vector squared. We define length as:
We can also measure angles between vectors:
The above is the for an angle between any two vectors in .
Additionally, these equations provide fundamental inequalities. Since , the Cauchy-Schwartz inequality follows,
Note that it is hard to visualise angles between . However, We measure the angle on the subspace created by the 2 vectors. In , any two vectors define a two-dimensional subplane, and therefore the angle is also well defined.
We will move now to the Inner Product, which will be defined after a quick discussion. Consider a function on an arbitrary interval . We want to measure the length and angle between any two functions. We will consider functions and . Now, the vectors:
With points, we have approximations to the functions in . Take their dot product:
An issues is this dot product is arbitrary depending on how we pick points . If the points are close together, perhaps we could derive a useful meaning about the functions. But including twice as many points will make the result nearly twice a big. Therefore, we include a factor for the distance between points:
The above is actually a Riemann Sum. And thus, why not let that distance approach ?
Definition 1.3.1 - The Inner Product: if and are two functions on an interval , we define their inner product to be:
definition of inner product
As long as the Riemann sum converges, it converges to the inner product.
Operations:
Moving onto Orthogonality! p. 12 Perpendicular, orthogonal, right angle, they imply the same thing in our context. Although, I believe perpendicular is more geared towards a plane in 3D space.
Fun identity, 2 vectors are orthogonal if their dot products, or inner products, are 0. This also happens with assuming the functions themselves are nonzero.
A set of functions is orthogonal if the dot product or inner product of every subset of two of them is 0. That can be a lot of math.
Collections of vectors or functions are orthonormal if they are orthogonal, and each has length 1, like a unit vector.
It is assumed the reader is familiar with Linear Algebra.
I will hopefully, one day, include a complete linear algebra section! Until then, I suppose having a quick recap can’t hurt anything besides my fingers from all of this typing…
We will cover the concepts of Eigenvectors and corresponding Eigenvalues , as the title suggests. For a square matrix :
Where is some scalar, and the pair together is called an eigenpair. Should be obvious that the direction is consistent, but the magnitude has changed. Even if , the vector points in the opposite direction but is still parallel.
A mention of common principles from Linear Algebra:
The author says that a Linear Algebra book will cover these important topics, so I’ll defer to that.
Then there is the fundamental idea of diagonalization. Suppose we have a matrix that has linearly independent eigenvectors , with corresponding eigenvalues , assuming all are real for now. For any -dimensional vector , we write:
equation 1.4
We then want to multiply matrix A by . Using linearity…
equation 1.5
However, if we know the eigenvalue, we can use that instead.
This is better for many reasons:
An additional restriction to diagonalization we must consider is that matrix must also have orthogonal eigenvectors. We mean the dot product:
Then, store these eigenvectors as columns of matrix and normalize the entries of that have length one, so . We now have
You can then write that:
Apply to to get the following:
Now, lets take it one piece at a time…
To simplify
Matrix multiplication has been reduces to a series of dot products with eigenvectors, multiplied by eigenvalues. This is sometimes called the EigenFunction approach.
p.14
Let’s start with eigenfunctions. In linear analysis, eigenfunctions are a special type of function that have a unique property when operated on by a linear operator. A linear operator is a mathematical operation that takes a function as input and produces another function as output.
When an eigenfunction is operated on by a linear operator, the resulting function is a scaled version of the original eigenfunction. In other words, the output is the same shape as the input, but it may be stretched or compressed by a certain factor. This scaling factor is called the eigenvalue.
To give you an analogy, think of a rubber band. If you stretch or compress the rubber band, it changes in size, but it retains its original shape. Similarly, an eigenfunction behaves like a rubber band under the action of a linear operator.
Now, let’s move on to diagonalization. Diagonalization is a process in linear analysis that allows us to simplify the representation of a linear operator. The goal is to find a special set of eigenfunctions that make the operator’s behavior easier to understand and work with.
When a linear operator is diagonalized, it means that its representation can be written as a diagonal matrix. A diagonal matrix is a square matrix where all the elements outside the main diagonal (from the top-left to the bottom-right) are zero. The values along the main diagonal correspond to the eigenvalues of the operator.
Diagonalization is useful because diagonal matrices have simpler properties compared to general matrices. Operations such as multiplication and exponentiation are much easier to perform on diagonal matrices.
To illustrate diagonalization, imagine you have a box of differently sized rubber bands (representing eigenfunctions) and a stretching machine (representing the linear operator). You put the rubber bands into the machine, and out comes a collection of rubber bands, each stretched or compressed by a certain factor. If you arrange these rubber bands according to their stretch factors, you end up with a diagonal configuration where each rubber band represents an eigenfunction, and the stretch factor represents the eigenvalue.
By diagonalizing a linear operator, we gain insights into its behavior and can perform calculations more efficiently.
Consider the following:
Letting will eliminate the cosine factor and also give us the initial displacement of the system. Notice that the frequency of the time variation, the cosine factor, is tied to the frequency of the spatial variation, the sine factor. This is the fundamental nature of the wave equation, discussed in at a later time.
Fourier Analysis is involved in many studies that are centred around waves, like study of light and optics, sound, etc… When you learn Fourier Analysis, you position yourself to better understand that entire list of topics.
We will typically refer to the Fourier Transform of a function as:
An author, Rob Bracewell, of another esteemed book, refers to the following:
This is a quick introduction into the basics where the reader can then dive further into interesting topics on their own.
Definition 2.1.1 The set of functions whose squared integral is finite, i.e. is referred to as , the square integrable functions on .
The square integrable functions for the space of functions that we are interested in. Also consider:
call it equation 2.1
The first 2 integrals are finite because . The last integral is finite because of Cauchy-Schwartz Theorem:
Therefore we can say it is a vector space. Of course, the proof of when the functions are complex would be left as an exercise because why sell a book that actually explains everything?
Theorem 2.1.1 Let be any function in . Then, we can represent in a series as
Where
This means you can represent any function in as the sum of sines and cosines.
Theorem 2.1.2 Let f(t) be any function in . We can represent in a series as:
Where
Additionally
Theorem 2.1.2 is just a generalisation of 2.1.1.
We can now simplify the theorem if the interval is centered about the origin, and .
Corollary 2.1.3 Let be any function in . Then, we can represent in a series as:
Where
The author then explains how to get from theorem 2.1.1 to 2.1.2 in case you have trouble memorizing, or looking them up.
The issue is that we have to calculate an infinite number of integrals. You can actually calculate them simultaneously. However, the Fourier Series cannot typically be easily calculated by hand.
As an example, consider the characteristic function on to be:
Other ways you may see this function are…
or
We would like to start by calculating our coefficients.
Definition 2.1.2 - Even and Odd Functions: A function is said to be even if . And it is odd if .
This matters because cosine is even and sine is odd. If is odd, then . Additionally, the products of these functions corresponds to positive and negatives. So, if is even, then is odd, and terms will zero out. The logic being that even functions can be represented entirely by cosine terms. Opposite logic applies if is odd.
We note that is even.
We now solve for terms in 2 parts, which is a plug and chug scenario based on substituting values in from our characteristic function. The author uses the odd property of sine that .
The author continues to arrive at
Remember, this is a transformation. So, it still represents the original function, just in a different context. But an infinite sum isn’t really programmable. As get bigger, the denominator grows, and therefore the result continues to decrease. We can probably take a partial sum as a good approximation, written as follows:
How many terms makes a good approximation? Might be useful to look at an error metric.
The next example would be the super simple function on the interval from . Off the bat, note that this is an odd function, so it will be exclusively defined through sine. Then, calculate the coefficient using integration-by-parts.
You can probably tell that more complex functions get out of hand. We will look into other methods of calculating the coefficients, probably numerical approximations.
Fourier Series can approximate nearly any function over a finite interval. Don’t make the mistake of believing that the FS will represent anything outside an interval though. Coefficients were determined and depend on in that interval.
Also, doesn’t necessarily need to be periodic at all. Thus, again, we can’t expect to represent outside of the defined interval. We may also use the notation to denota the Fourier Series on .
We are now looking into the function of the Four Series.
The right is an infinite sum. We want to say the limit as the number of terms approaches infinity converges to , but that’s apparently not correct.
We define:
and the error function is:
As the limit of our terms approachs infinity, the error will approach 0 for any function . Beyond our scope, research books that discuss the relative convergence rates of Fourier Series.
Compute the Fourier Series for the function:
on . Plot some terms both in and outside the interval.
Try to compute it now on a larger interval, like .
Try and on similar intervals. It’s mostly finding sine and cosine coefficients.
Orthogonality and perpendicularity are the same concepts, used interchangeably. However, we typically say orthogonal when dealing with dimensional vector spaces greater than 3 dimensions, or the function spaces, like .
Dot product: defined here
Euclidean distance:
Angle between vectors: .
We now want to compare two functions and . Consider finite number of points , where and on the interval .
Distance between each point is defined as .
We want to approximate the length of these functions by their vector counterparts.
However, if we have more points, then the length could double. So, we then multiply in
Thus, on the same interval, if we cut it put into more pieces, each piece has a smaller weight.
Definition 2.2.1 - Inner Product: if and are functions in , then we define the inner product as:
And the length of would be
We used complex conjugate in the inner product definition, which is a number with equal real and imaginary parts, equal in magnitude but opposite in their sign.
Standard Linear Algebra, or linear analysis, texts should dive into details about the inner product.
Stating the important properties inhertied by :
The equality holds only if is a constant multiple of , .
Definition 2.2.2.a Two functions and in are said to be orthogonal if . A collection or set of functions is orthogonal if for any pair of functions from the set where .
Definition 2.2.2.b We say that a set of functions is orthonormal if they are orthogonal, and they all have length one, .
Theorem 2.2.1 - Orthogonality: The functions and are orthogonal on the interval . Additionally, functions used in Theorem 2.1.2 are also orthogonal on corresponding interval .
Proofs on pp. 32-33
Because of odd and even trig functions
Thus, cosines are orthogonal to all sines.
Interesting as well, given double angle trigonometric identities…
The proof goes on to prove cosines are cosines are orthogonal to each other and similar logic for sines orthogonal to each other as well.
Completeness refers to having enough functions for the expansions we are suggesting. It’s beyond the scope of the text. The author provides a proof of completeness pp. 33-34.
Theorem 2.2.2 Let be a complete set of orthonormal functions in then for any function in that space:
It’s fundamental to Fourier Analysis. Note that a vector space is a set of elements, called vectors, that can be added together and multiplied by scalars. The Hilbert space is a vector space where the inner product also lives as a distances function.
Further, but not necessary, a Euclidean space are intended to represent physical space.
Theorem 2.3.1 - Pythagorean Theorem: let be a function in a Hilbert space , like . Let be a complete set of orthonormal functions and be an element of . The squared length of can be represented as:
There’s a proof on p.36
… skipping ahead to convolution for time sake…
Definition 2.8.1 - Convolution and Correlation: Let , and by extensions . The convolution of and is:
And the correlation of and is:
Subtle difference in the function . We want to characterize the Fourier Series of these two function. I think it’s basically taking 2 functions and making a third function.
Theorem 2.8.1 - Convolution and Correlation Theorem: Let . the convolution will be in . Further, the Fourier Series of on , denoted , expressed as:
The Fourier Series of correlation is:
maps the function to its Fourier Coefficients.
Proof found on p. 66.
We continue to skip Chapter 3 which is the Discrete Fourier Transform
We relax the assumption that , the Fourier series is:
You can write the frequency as to rewrite the above equation.
We also previously too the period to be a finite interval after which the function repeats itself. But we can also consider the limit of large periods, . What would happen is that the difference in frequencies in sine and cosine terms becomes infinitesimally small and they become a continuum.
Recall coefficients are given by:
Substitute this expression into the complex Fourier Series,
It looks complicated, but if we let , then . This simplifies to:
We apparently chose . Put it together:
And we now define the Fourier transform of to be:
And we also have an inverse Fourier Transformation as:
With the Fourier transformation, we can switch between equivalent views of analysing a signal, the observable domain or the frequency domain. You may see instead of because of the dependency on time.
This helps apply frequency filters.
Example says to find the Fourier Transform of assuming that .
title: Advanced Mathematics
subtitle: DLMDSAM01
Author: Dr. Robert Graf
publisher: IU International University of Applied Sciences
year: 2023Recommends “Signals & Systems” by Oppenheim et al., 1997.
p.47 / 49
We want to cover:
A function space is a set of functions between 2 fixed sets.
A Transformation function is a function that maps a set to itself (i.e. ). An example is a linear transformation, which is a linear algebra concept of a linear map that maps between 2 vector spaces. A vector space is a set of elements called vectors. In geometry, we can transform coordinates from coordinates from one system to the another, like from Cartesian to Polar.
An Integral Transformation maps a function from its original function space into another function space via integration. An integral transform is any transform of the following form:
The input of the transform is a function , and the output is another function . An integral transform is a particular kind of mathematical operator. The function is called the kernel function, or integral kernel in our case. It may also be referred to as the nucleus of the transform.
Some kernels even have an inverse kernel that can yield an inverse transform;
But for now, this is beyond the scope of learning. A symmetric kernel is one that is unchanged when the 2 independent variables are permuted, .
A good example of integral transforms is the Laplace transform, a concept in differential equations. There’s also the path integral. The Wiki article has a table of integral transforms as well.
In this unit, we will be interested in looking into Convolutions and Fourier transform.
There’s a little background information we need to discuss before we dive into the maths.
We take resolution to mean that detectors are not infinitely precise but can only measure a quantity up to a certain precision determined by the resolution of the detector. I guess it’s like the “limit of accuracy”, but not “limit” in the calculus sense. Like how a rules might have cm and mm. It’s resolution is therefore down to mm as it can’t measure more precisely.
So, there’s not a mathematical property associated with the concept. If we keep repeating the same measurement, we will get slightly different results for the same “true” physical values that are determined by the intrinsic resolution of the device. It’s more or less governed by probabilities and probability distributions.
An unbiased measurement does not shift the “true” value. It returns values around the same true value that may randomly and slightly fluctuate. Example could be a thermometer.
By repeating the measurement many times, it is possible to determine the resolution of the instrument, and hence the intrinsic volatility of the measurements made. That is probably statistics with measurements centred around a normal distribution. The lower the resolution, the wider the spread across the normal curve (larger variance).
Deviations from the normal curve, perhaps with a tail of sorts, is an indication of bias as the resolution of the instrument is asymmetric.
In a way, we are approaching some function…
where we have the true value of what is being measured with a hint of random error. Sorry for the wording, I’ve had maybe 3 hours of sleep and am on the train to Dublin at the moment.
Many, many systems, objects, and processes are stochastic. By stochastic, we mean that stochastic systems are governed by the laws of probability, as opposed to deterministic systems that can be calculated precisely. Stochastic processes is an entirely fun topic including Brownian Motion and Markov Chains.
Many measurements we observe are random, but follow a distinct probability distribution governed by a specific process relevant for that system. Therefore, our would describe a distribution in some way.
Let’s begin building:
Our independent variables all represent the actual true measurement, like a temperature. However, they each enter the consideration at “a different point,” influenced by different parts.
Essentially, the true value is a random number taken from probability distribution . If it is a continuous probability distribution, the probability of obtaining any exact number is 0, because of technical infinite possibilities. Thus, we must calculate probability of getting true value in the interval with .
Our measuring instrument will (generally) shift the true value towards the observed value. We will not observe , but , shifted by amount .
In general, we do no know true value of . If our instrument is unbiased, the resolution will smear the true values evenly. And if biased, there will be an additional shift in one direction. Hence, the original interval is transformed into the interval . The overall effect of the instrument is given by .
For a particular observation, we combine the probabilities to obtain . To express this for any value, we integrate over all possible values of to obtain the distribution for all observable values of :
equation 2.1 The Convolution of functions and , typically denoted .
Page 51 of book looks at uniform distributions, but then states that’s not common in practice. You are more likely to see something like a true value represented by (Gamma) functions. A measurement device represented by an unbiased Gaussian resolution function with , and .
Interesting consideration are measurements that may violate physical boundaries. These should be treated with extra consideration.
Why are we talking so much about Convolutions? Well, they are an integral part of image processing and usually at the core of image filters. Additionally, as the name suggests, they are kind of at the core of convolutional neural networks.
We would consider , the true values, be the actual image itself. Then, is the kernel bound by a more literal resolution, and operates on the image. Hence, we can now consider a wide range of applications such as blurring, sharpening, and edge detection!
Note: the kernel is often denoted by either or .
It might be easiest to discuss how convolution can be used to blur an image. To do this, each part of the image is convolved with a Gaussian filter in the and directions. That is, we apply a two-dimensional (multivariate) Gaussian to each part of the image. Because images are typically represented by a collection of individual pixels , the continuous convolution integral, in a discrete case, will look like:
So, in the case of Gaussian blurring, the kernel is given by a matrix like:
The matrix is applied to each part of the image. The value of each pixel is transformed and influenced by its neighbouring pixels. Relative weights are given by the kernel.
Take care at the edges where the kernel can potentially exceed the image boundaries. Here, you can either extend the image (e.g. repeat outermost pixels), or crop the image so the Kernel always fits inside the original image.
This is a very interesting concept, maybe worth trying to implement.
p. 54
Using Taylor expansions, we can approximate a signal or a function. The Fourier series is another way to do this, but is better suited to periodic signals like those found in natural and engineering systems. The main idea of the Fourier Series is to express the signal as a sum of sine and cosine waves with varying strengths and frequencies.
To create a Fourier Series for a function, the signal must satisfy the following Dirichlet conditions:
Interesting: The requirement that a function is periodic can be stated as the following condition:
You can see that the function repeats itself after the full period has passed. It also implies the signal has no beginning nor an end. Usually, is used instead of to denote a single full period.
The Fourier series promised decomposition of a signal into a summation is given by:
equation 2.4
That looks complicated. If we let the period , it will simplify:
equation 2.5
A sinusoidal signal is fancy for sine wave. We look at and discuss the Sawtooth Signal because it is actually a realistic signal that is frequently encountered in electrical engineering. The images in the book cover the transformation from time domain to frequency domain. It is interesting to contrast the Saw Tooth, composed of many, many frequencies, to just a smooth sine wave.
side note - Euler’s formula casually dropped
Euler’s Formula
We can represent the sine and cosine terms in the Fourier Series by exponential function with imaginary arguments using Euler’s Formula as follows:
We can carefully the insert them into our previous equation 2.5…
This last part isn’t explained well in the text, just kinda put there for some reason. I left it out until I understand more.
Basically,
It looks confusing that the coefficient is a function of itself, but that is part of the transformation. We aren’t creating something new, but redefining it to mean the same thing, just with trigonometry.
We relax the assumption that , the Fourier series is:
You can write the frequency as to rewrite the above equation.
We also previously too the period to be a finite interval after which the function repeats itself. But we can also consider the limit of large periods, . What would happen is that the difference in frequencies in sine and cosine terms becomes infinitesimally small and they become a continuum.
Recall coefficients are given by:
Substitute this expression into the complex Fourier Series,
It looks complicated, but if we let , then . This simplifies to:
We apparently chose . Put it together:
And we now define the Fourier transform of to be:
And we also have an inverse Fourier Transformation as:
With the Fourier transformation, we can switch between equivalent views of analysing a signal, the observable domain or the frequency domain. You may see instead of because of the dependency on time.
This helps apply frequency filters.
Example says to find the Fourier Transform of assuming that .
Quiz:
This integral is a well-known result in mathematics and is often referred to as the Gaussian integral. It’s a special case of the more general Gaussian integral used in probability theory and statistics.
To show how this result is true, we can use a technique involving polar coordinates. Let’s consider the integral:
First, we’ll square this integral:
Now, we’ll change to polar coordinates by considering and . The Jacobian determinant for this transformation is , and we integrate from to and from to :
The inner integral with respect to (\theta) gives (2\pi), and the outer integral can be evaluated using the substitution :
Therefore, , which proves the result you stated:
This integral is significant in various fields such as probability, statistics, and physics, where the Gaussian distribution appears frequently due to its various properties.
Let’s break down the process step by step.
Squaring the Initial Integral: When we square the initial integral, we are essentially considering the product of two identical integrals. The variables (u) and (v) are just dummy variables of integration, so they don’t have any special meaning beyond that. This step is a mathematical trick that helps us transform the problem into one that can be tackled using polar coordinates.
Introducing Polar Coordinates: In order to perform the integration in a different coordinate system (polar coordinates), we introduce a new set of variables (r) and (\theta) to replace (u) and (v). This is a common technique in integration, especially when dealing with problems involving circular symmetry. The variables (r) and (\theta) describe points in the plane in terms of distance from the origin and angle from the positive x-axis, respectively.
The Jacobian Determinant: When you change from one set of variables to another, like going from Cartesian coordinates ((u, v)) to polar coordinates ((r, \theta)), you need to account for how the infinitesimal areas change. This is where the Jacobian determinant comes in. The Jacobian determinant is the determinant of the matrix of partial derivatives of the new variables with respect to the old variables. In this case, it’s the determinant of the matrix:
[ \begin{bmatrix} \frac{\partial u}{\partial r} & \frac{\partial u}{\partial \theta} \ \frac{\partial v}{\partial r} & \frac{\partial v}{\partial \theta} \end{bmatrix} ]
In polar coordinates, (u = r\cos(\theta)) and (v = r\sin(\theta)). So, the matrix becomes:
[ \begin{bmatrix} \cos(\theta) & -r\sin(\theta) \ \sin(\theta) & r\cos(\theta) \end{bmatrix} ]
The determinant of this matrix is (r), which is why you see (r) appearing when changing variables in the integral. The Jacobian determinant captures how the area element in the new coordinate system scales compared to the area element in the old coordinate system.
When performing a change of variables in integration, you need to adjust the integrand by multiplying it by the absolute value of the Jacobian determinant, which ensures that you’re properly accounting for the change in variables. In this case, the Jacobian determinant is (r), so when we change variables from (u, v) to (r, \theta), the new integrand becomes (r) times the original integrand. That’s why you see the (r) factor when transforming the integral.
I hope this helps clarify the process! If you have any more questions, feel free to ask.
url: https://betterexplained.com/articles/intuitive-convolution/As Always, check out Supported Functions · KaTeX for support.
Per Better Explained, the fomal definition of a convolution is:
Many people might describe it as sliding windows as they try to escape through one, I can see that actually. If you ignore the integral, a convolution is just “fancy multiplication”.
This is actually a really good example. All credit given to Better Explained. You can relate it to Covid-19. Say we have the vaccine, or treatment for sick patients (either works), and the does is 3 units. Let you patients for the week be 1, 2, 3, 4, and 5 on Friday.
How much medicine do we use each day?
What if one does wan’t enough though? Suppose we had to give 3 units on the first day, 2 on the second, and then 1 on the third. The patient’s schedules overlap and it becomes… convoluted?
It’s perfect if you use a monospace font. But you can see how we can slide the dosage over the patients day over day. We can multiply those and get an answer. Hense, fancy multiplication.
The result of a convolution is a new function. Additionally, since we pass arguments into function, we can think of them as lists, a list of arguments. But the convolution actually reverses on of the lists. Even in the example above, as we slid the dose over the patients, the dose should be [3, 2, 1], starting with 3 and ending with 1. However, for the example to work we reversed that.
Also note that if you reverse the patients instead, you would obtain the same results. I think that is communtative.
In the mathematical expression, the is the unaltered list, and the is the reversed list.
To convolve a kernel with an input signal, flip the signal, move to the desired time, and accumulate every interaction with the kernel.
For , it’s customary to use as the dummy variable.
A convolution is communtative!
Going back to the medicine example, the integral of the convolution is the total sum of medicine. The convolution at each point is the medicine per day, and the integral is the total in a given amount of time.
Check this out. Our plan originally gave each patient total units of medicine. And there were total patients. So the total units used is units! That is
Note that this only applies to convolutions and not to general integrals. Therefore let it be stated that,
If you let , you can see that the integral of the product would evaluate to , but the product of the integrals would be more like .
This is just a quick introduction, there’s another article on the Fourier Transform I will also cover. I hear we use the fancy to represent the Fourier series. It’s objective is to convert a function into a list of cyclical ingredients .
Think of it as an operator like
A Fourier series has more to do with frequency. In fact, I think the function needs to be periodic. So, the Fourier series give us a list of ingredients.
For a simple math understanding, the Fourier Transform maps a function from a time based domain to a frequency based domain. I believe that is right. On a chart, if the x-axis is time, it would change to frequency, or the period of the function. A complex function, broken into many different sine and cosine waves, and mixed together with many different weights, would then fill many frequencies in a histogram fashion, where the period on the x-axis, and the weight on the y-axis (I think).
A convolution (fancy multiplication) in the time domain is is multiplication in the frequency (Fourier) domain. So, if we map a convolution with a Fourier Transform, it becomes the multiplication of those transforms,
So, for as a Fourier Transform of , we pass in a specific frequency and it (should) return the combined interaction of all data points with that frequency.
Amazingly, it works backwards as well.
So, regular multiplication in the time domain becomes a fancy multiplication in the frequency domain.
Image blurring is a popular application. You can also unblur with the convolution theorem. The math is amusing.
Then there is the Convolutional Neural Nets, where the input signal is convolved with many kernels. The algorithm optimizes kernel weights to improve output.
url: https://betterexplained.com/articles/an-interactive-guide-to-the-fourier-transform/An Interactive Guide To The Fourier Transform – BetterExplained
More soon…